
Ruizhe Chen is currently a Ph.D. candidate in Computer Science at Zhejiang University, advised by Prof. Zuozhu Liu, and I expect to graduate in June 2026. My research centers on large-model post-training and multimodal video understanding. Previously, I contributed to Qwen3-VL with Alibaba’s Qwen team. I’ve published in top venues including NeurIPS, ICLR, ACL, EMNLP, and NAACL. I’m currently seeking positions focused on large multimodal models, especially video-LLMs.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Zhejiang UniversityDepartment of Computer Science
Zhejiang UniversityDepartment of Computer Science
Ph.D. StudentSep. 2021 - present -
Zhejiang UniversityB.S. in Electrical EngineeringSep. 2017 - Jul. 2021
Work Experience
-
 Qwen Team, Alibaba GroupContribute to Qwen3-VL with a focus on Video Understanding and Agentic RL.Research Intern2025
Qwen Team, Alibaba GroupContribute to Qwen3-VL with a focus on Video Understanding and Agentic RL.Research Intern2025
News
Selected Publications (view all )
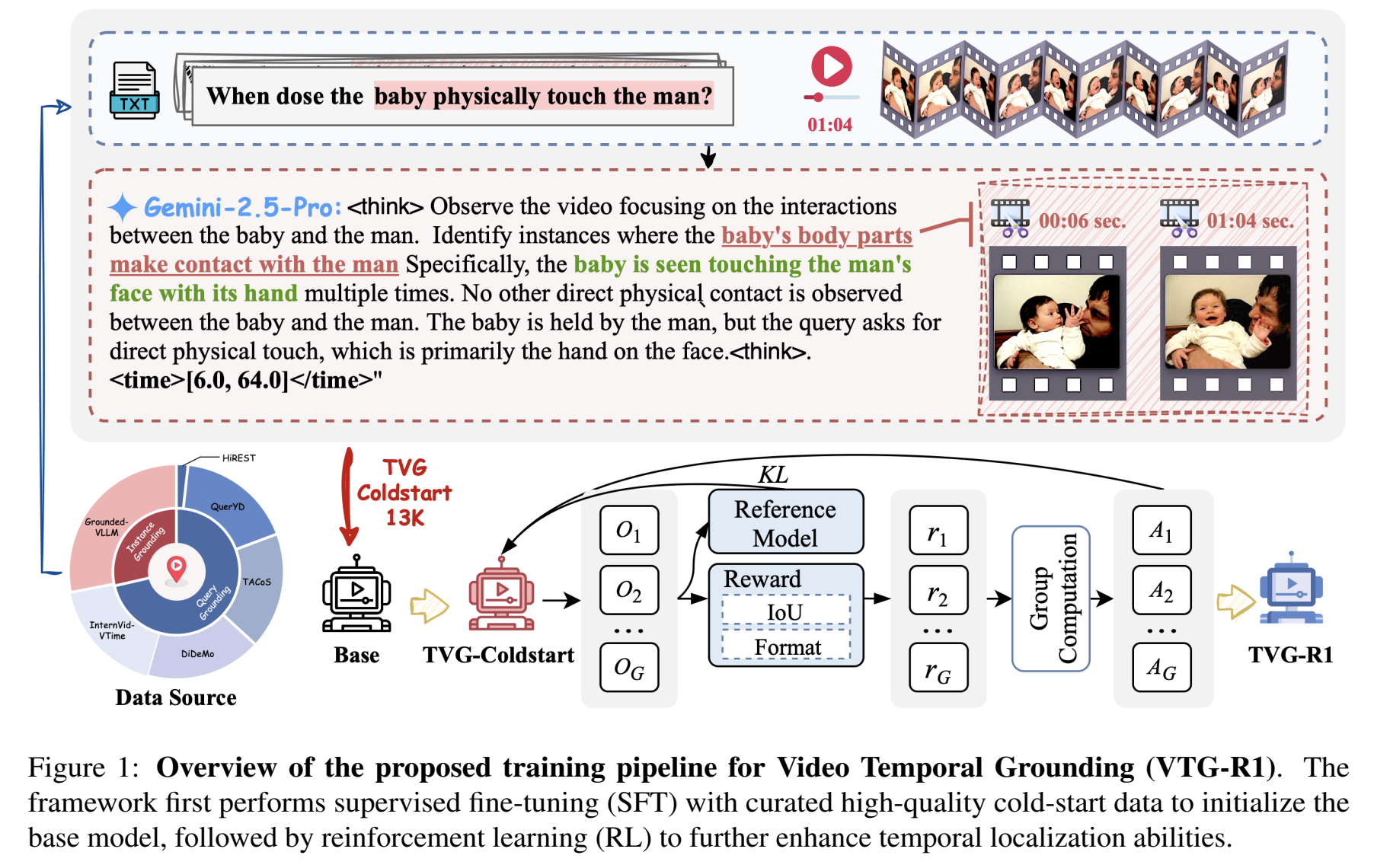
Datasets and Recipes for Video Temporal Grounding via Reinforcement Learning
EMNLP 2025
This paper introduces a two-stage SFT+RL framework that improves Video Temporal Grounding accuracy and robustness.
Datasets and Recipes for Video Temporal Grounding via Reinforcement Learning
EMNLP 2025
This paper introduces a two-stage SFT+RL framework that improves Video Temporal Grounding accuracy and robustness.
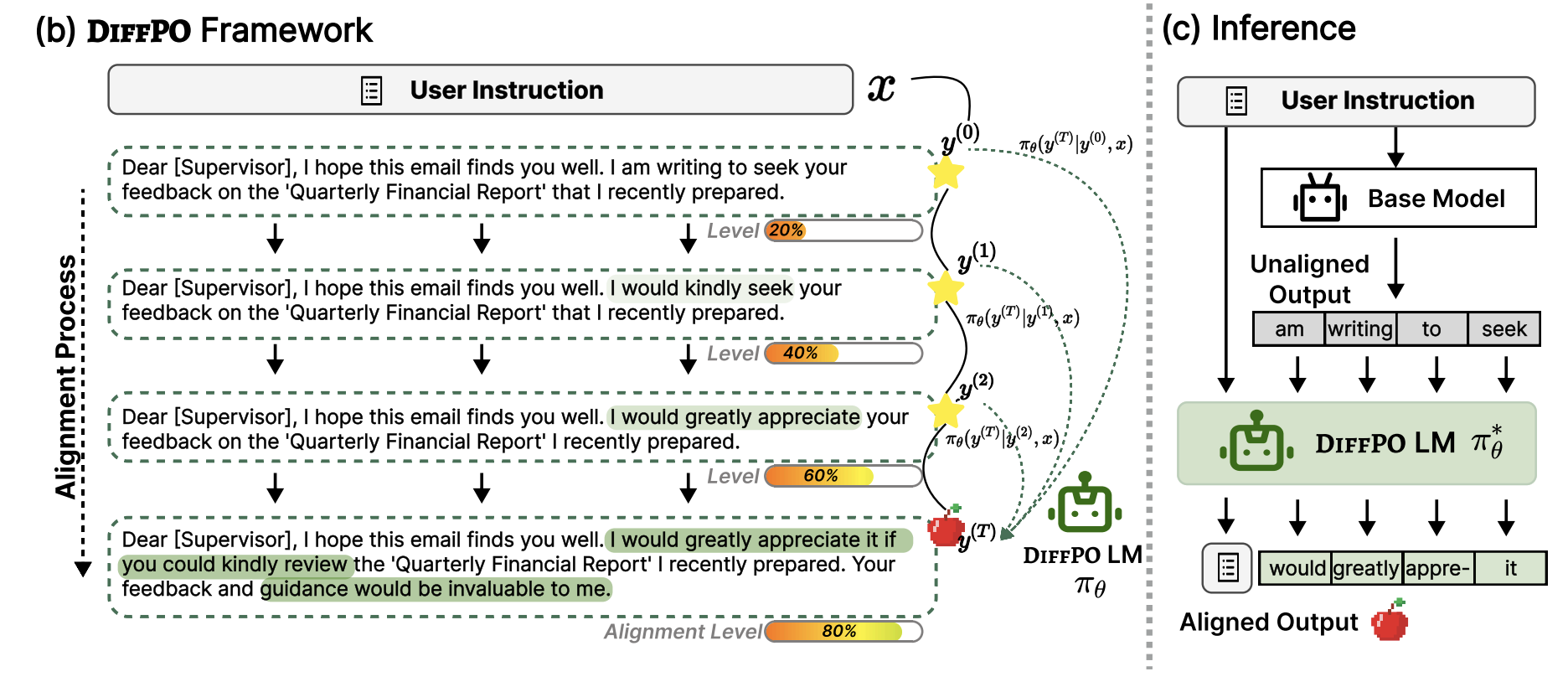
DiffPO: Diffusion-styled Preference Optimization for Efficient Inference-Time Alignment of Large Language Models
ACL 2025
Diffusion-styled Preference Optimization (DPO) is a plug-and-play, policy-agnostic inference-time alignment method that aligns LLMs at the sentence level to reduce latency while improving alignment quality across benchmarks and model scales.
DiffPO: Diffusion-styled Preference Optimization for Efficient Inference-Time Alignment of Large Language Models
ACL 2025
Diffusion-styled Preference Optimization (DPO) is a plug-and-play, policy-agnostic inference-time alignment method that aligns LLMs at the sentence level to reduce latency while improving alignment quality across benchmarks and model scales.
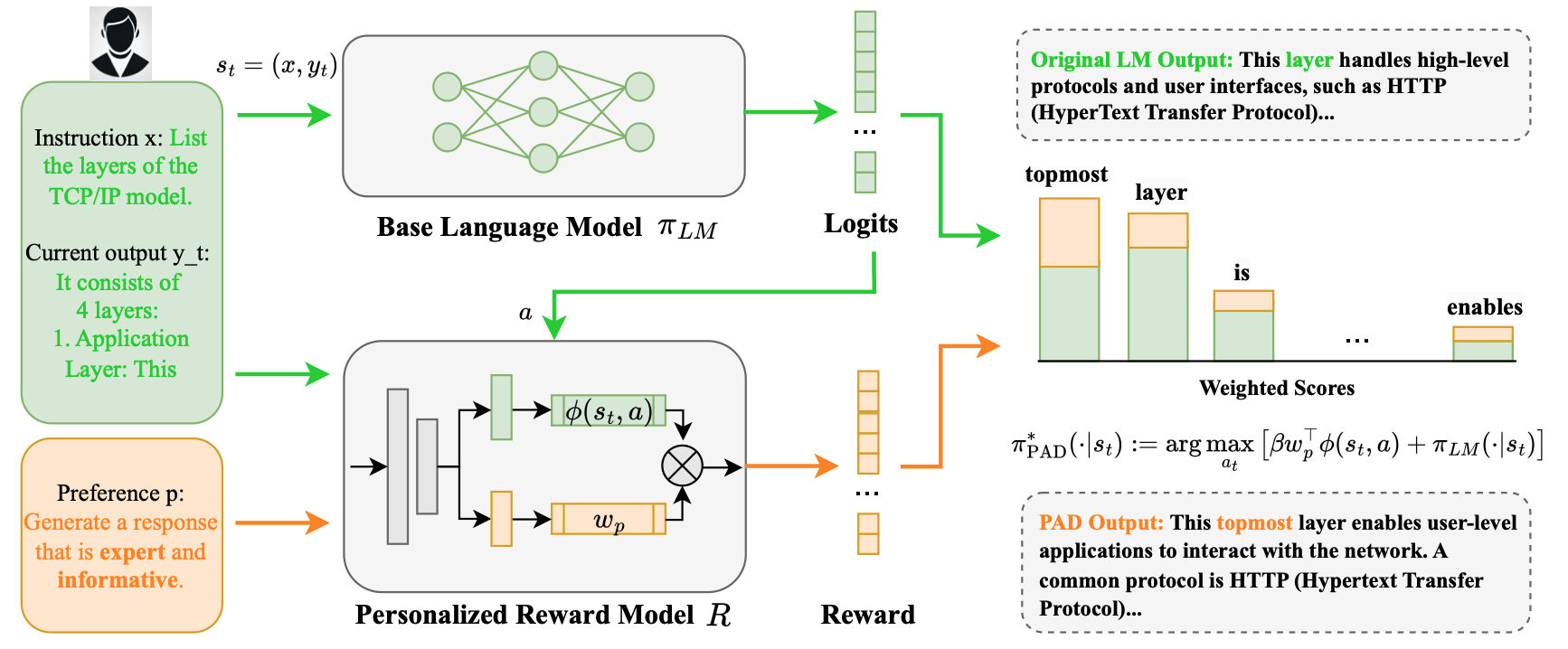
Pad: Personalized alignment of llms at decoding-time
Ruizhe Chen, Zuozhu Liu
ICLR 2025
Large Language Models Alignment.
Pad: Personalized alignment of llms at decoding-time
Ruizhe Chen, Zuozhu Liu
ICLR 2025
Large Language Models Alignment.
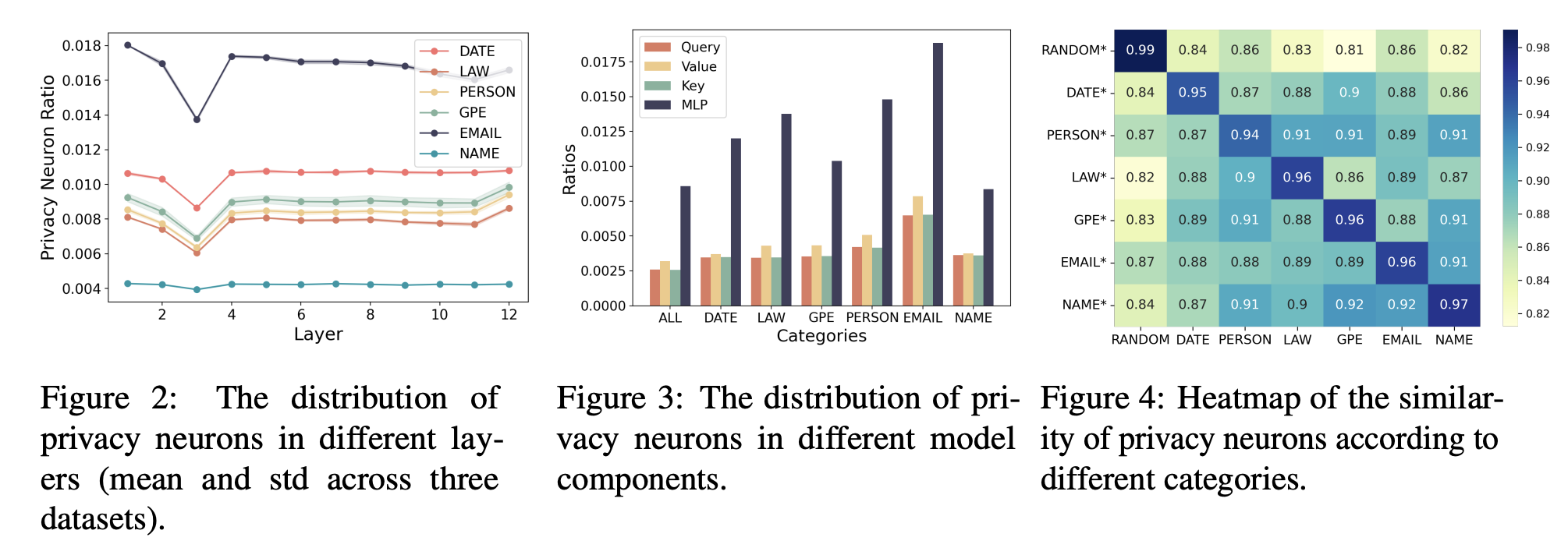
Learnable Privacy Neurons Localization in Language Models
Ruizhe Chen, Tianxiang Hu, Zuozhu Liu
The 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024 main) 2024
Large Language Models Safety (Privacy).
Learnable Privacy Neurons Localization in Language Models
Ruizhe Chen, Tianxiang Hu, Zuozhu Liu
The 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024 main) 2024
Large Language Models Safety (Privacy).
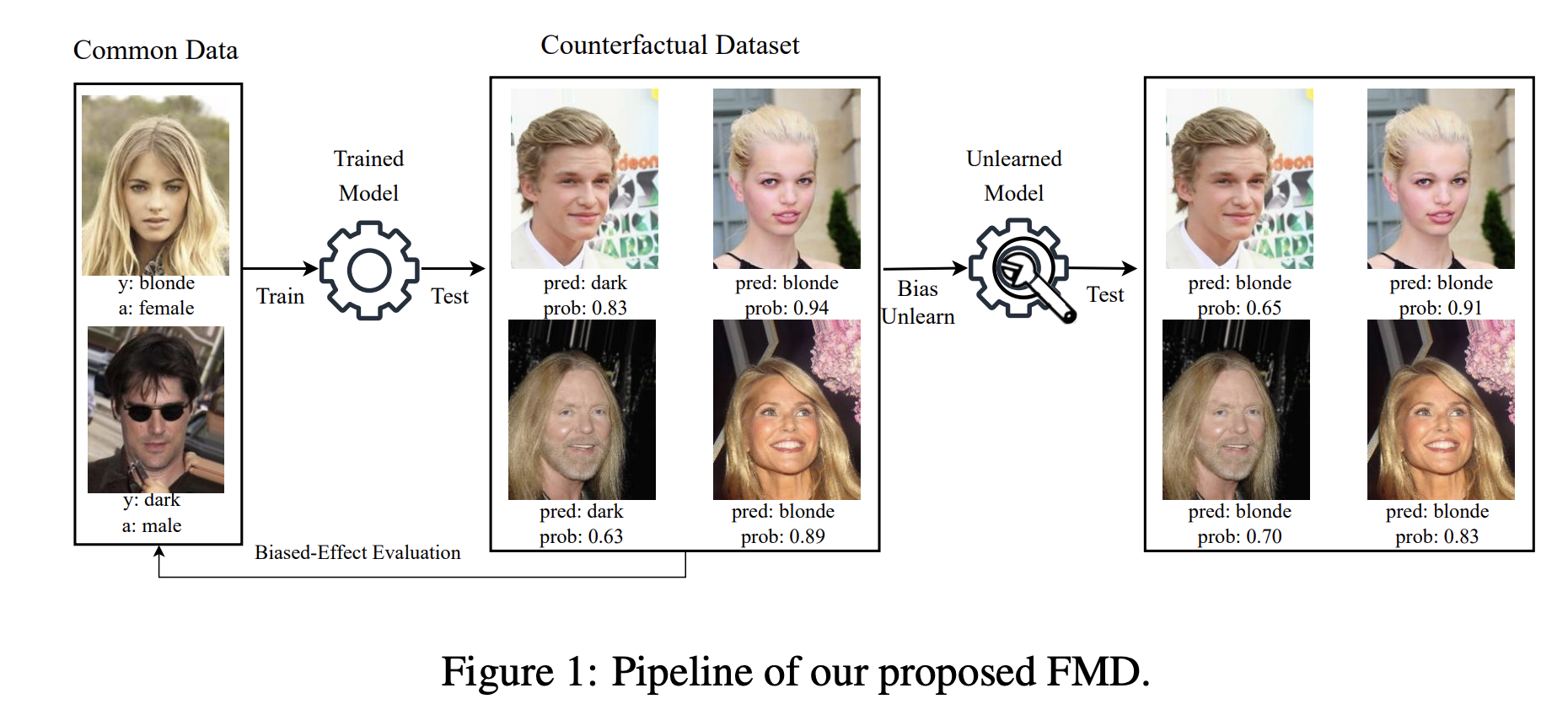
Fast model debias with machine unlearning
Ruizhe Chen, Jianfei Yang, Zuozhu Liu
Advances in Neural Information Processing Systems 2023
DL Fairness, Large Language Models Fairness, Machine Unlearning via Influence Function
Fast model debias with machine unlearning
Ruizhe Chen, Jianfei Yang, Zuozhu Liu
Advances in Neural Information Processing Systems 2023
DL Fairness, Large Language Models Fairness, Machine Unlearning via Influence Function